A Survey on Efficient Vision-Language-Action Models
1 School of Computer Science and Technology, Tongji University, China
2 School of Computing and Artificial Intelligence, Southwest Jiaotong University, China
3 School of Computer Science and Engineering, University of Electronic Science and Technology of China, China
4 Department of Information Engineering and Computer Science, University of Trento, Italy
Overview
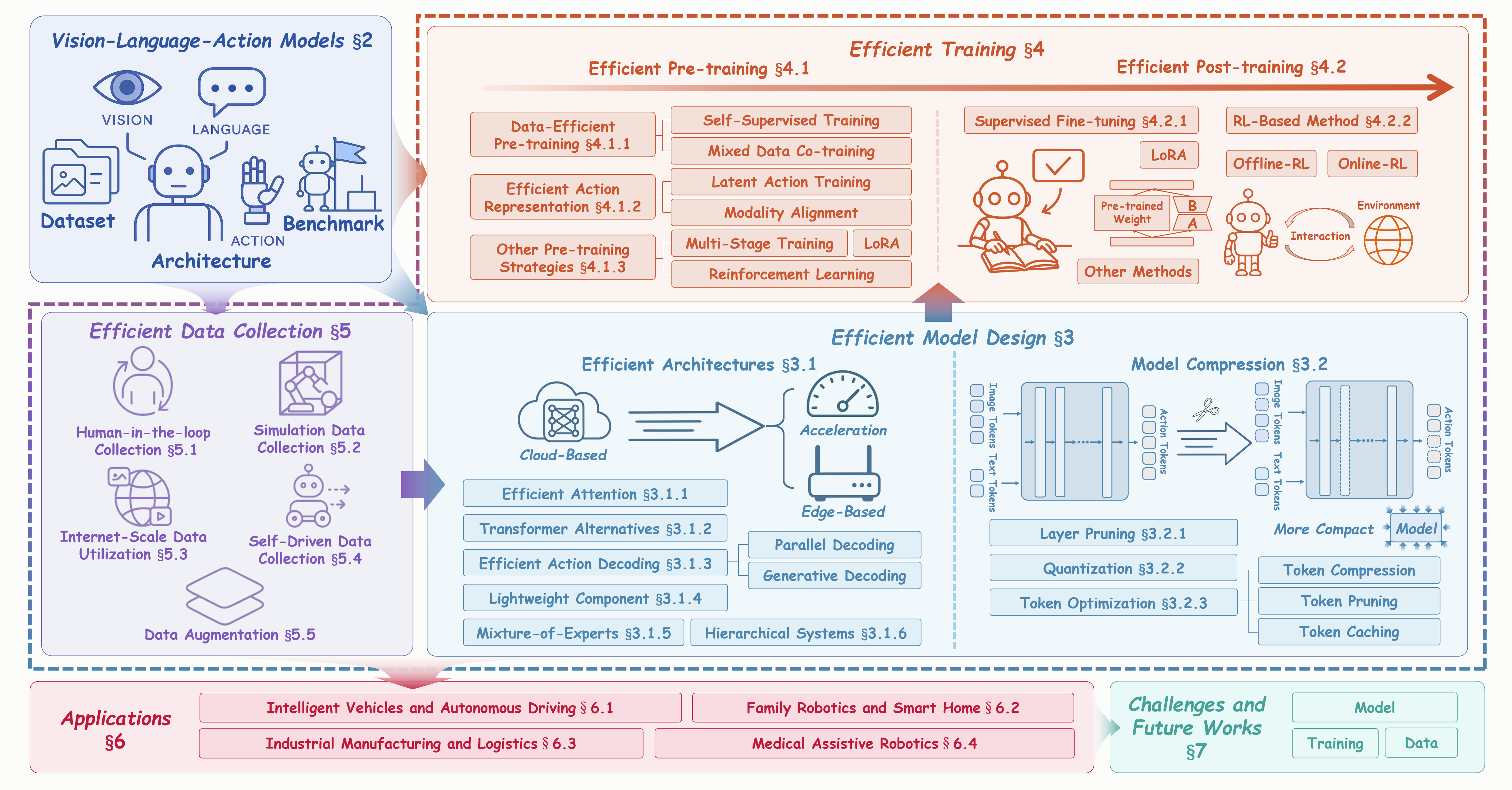
Figure: The Organization of Our Survey. We systematically categorize efficient Vision-Language-Action (VLA) models into three core pillars: (1) Efficient Model Design, encompassing efficient architectures and model compression techniques; (2) Efficient Training, covering efficient pre-training and post-training strategies; and (3) Efficient Data Collection, including efficient data collection and augmentation methods. The framework also reviews VLA foundations, key applications, and establishes the groundwork for advancing scalable embodied intelligence.
Abstract
Vision-Language-Action models (VLAs) represent a significant frontier in embodied intelligence, aiming to bridge digital knowledge with physical-world interaction. While these models have demonstrated remarkable generalist capabilities, their deployment is severely hampered by the substantial computational and data requirements inherent to their underlying large-scale foundation models. Motivated by the urgent need to address these challenges, this survey presents the first comprehensive review of Efficient Vision-Language-Action models (Efficient VLAs) across the entire data-model-training process. Specifically, we introduce a unified taxonomy to systematically organize the disparate efforts in this domain, categorizing current techniques into three core pillars: (1) Efficient Model Design, focusing on efficient architectures and model compression; (2) Efficient Training, which reduces computational burdens during model learning; and (3) Efficient Data Collection, which addresses the bottlenecks in acquiring and utilizing robotic data. Through a critical review of state-of-the-art methods within this framework, this survey not only establishes a foundational reference for the community but also summarizes representative applications, delineates key challenges, and charts a roadmap for future research.
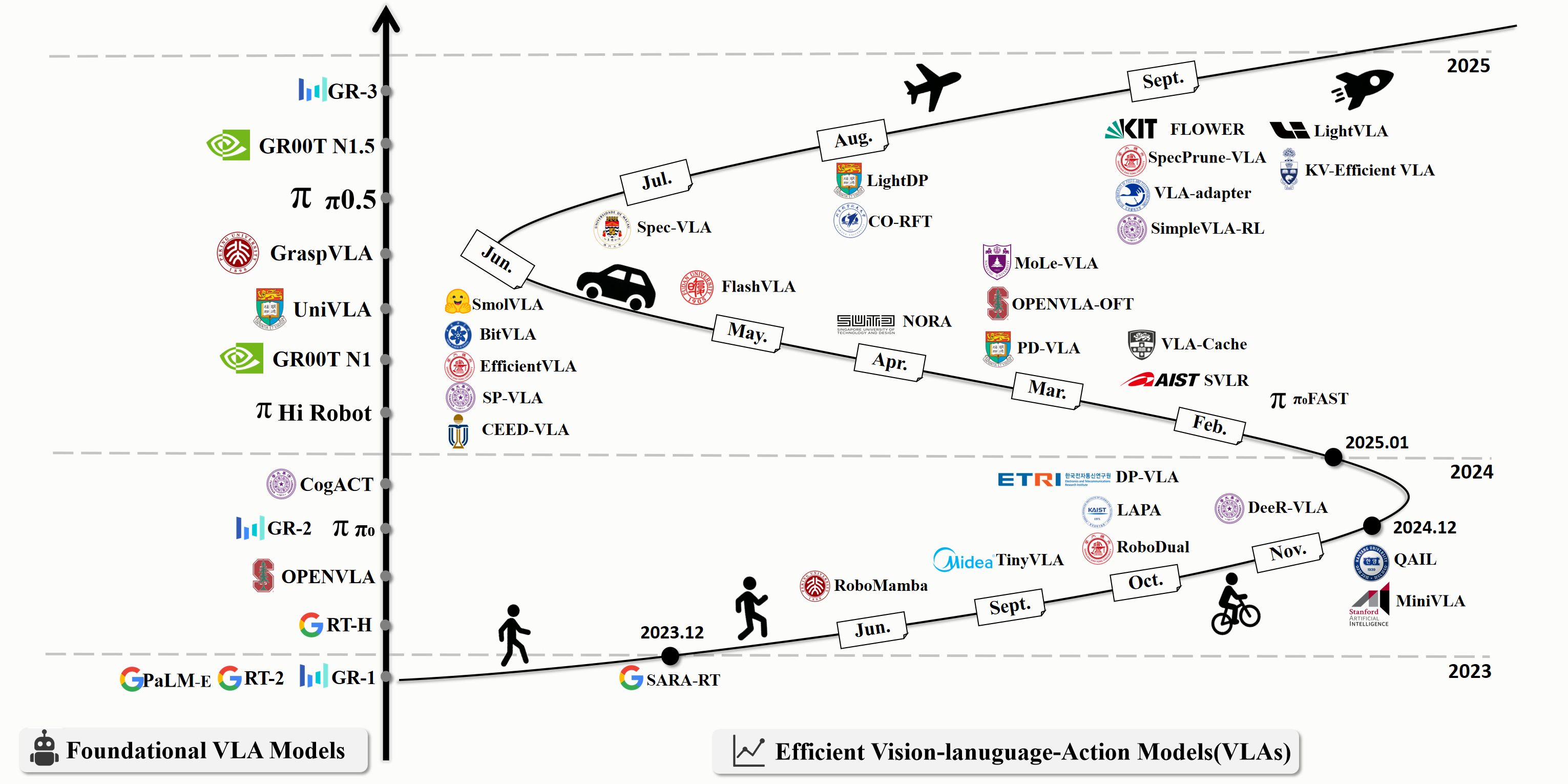
Figure: Timeline of Foundational VLA Models and Efficient VLAs. The timeline illustrates the progression of foundational VLA models and efficient VLAs from 2023 to 2025, highlighting the explosive growth in enhancing the efficiency of VLA to bridge computational demands with real-world robotic deployment.
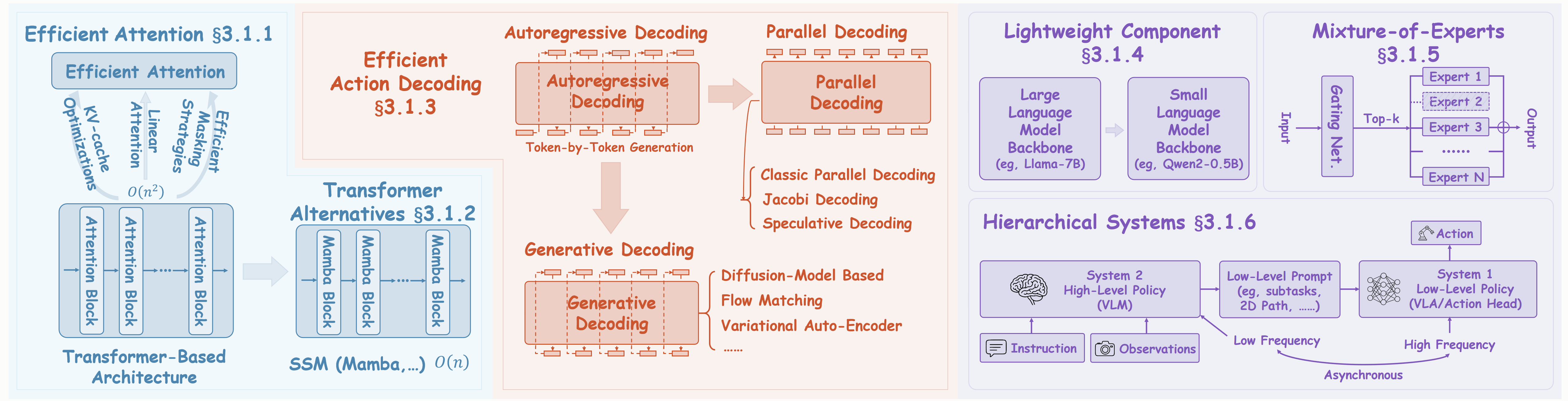
Figure: Efficient Model Design. Efficient Architectures: We illustrate six primary approaches: (a) Efficient Attention (b) Transformer Alternatives (c) Efficient Action Decoding (d) Lightweight Components (e) Mixture-of-Experts and (f) Hierarchical Systems.
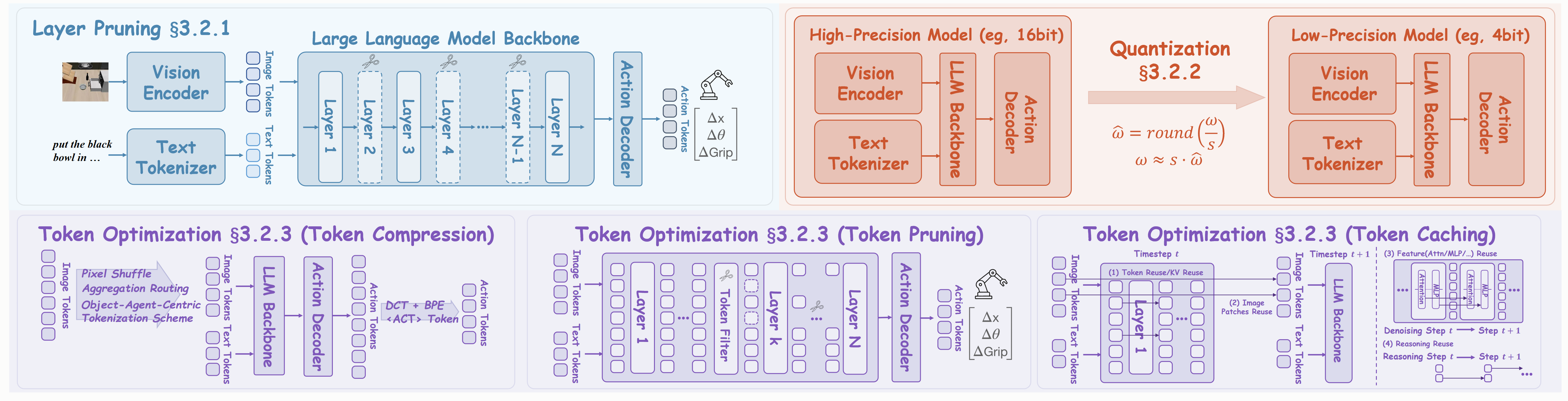
Figure: Efficient Model Design. Model Compression: We illustrate three primary approaches: (a) Layer Pruning (b) Quantization (c) Token Optimization.
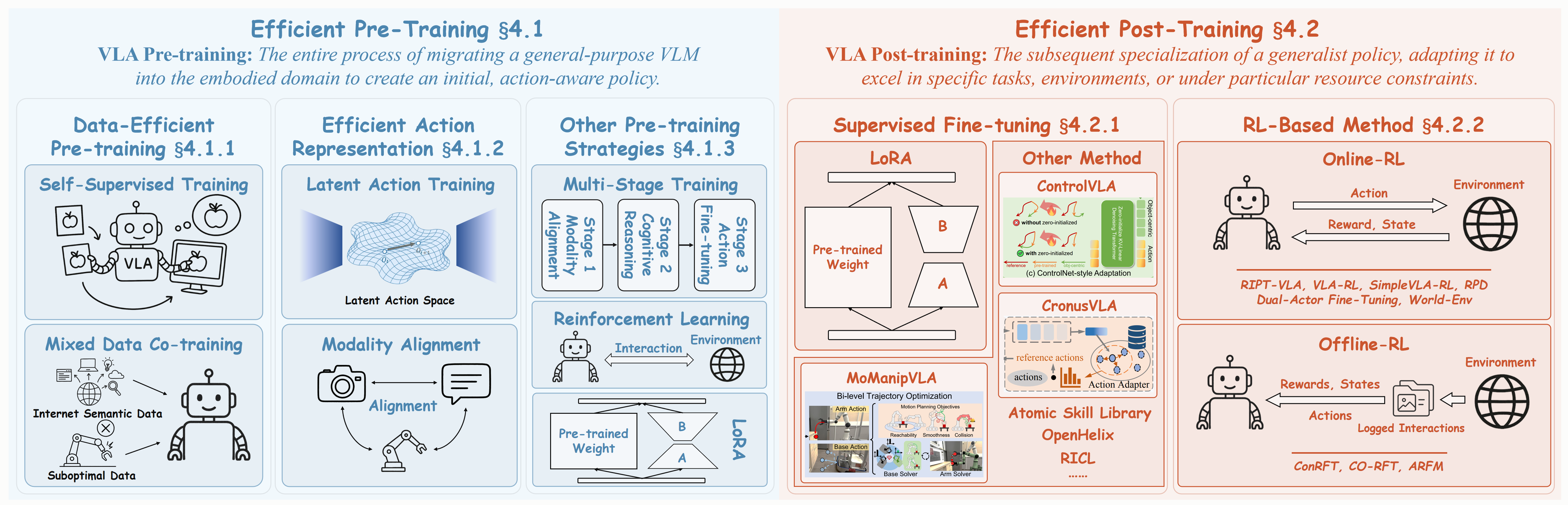
Figure: Efficient Training in VLAs, divided into two main stages. (a) Efficient Pre-Training (b) Efficient Post-Training.

Figure: Efficient Data Collection Strategies in VLAs. This figure illustrates the primary approaches under efficient data collection, encompassing human-in-the-loop, simulated, reusability-oriented, self-driven, and augmentative techniques for scalable acquisition of high-quality robotic datasets while minimizing resource overhead.
Citation
@misc{yu2025efficientvlassurvey,
title={A Survey on Efficient Vision-Language-Action Models},
author={Zhaoshu Yu and Bo Wang and Pengpeng Zeng and Haonan Zhang and Ji Zhang and Lianli Gao and Jingkuan Song and Nicu Sebe and Heng Tao Shen},
year={2025},
eprint={2510.24795},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.24795},
}