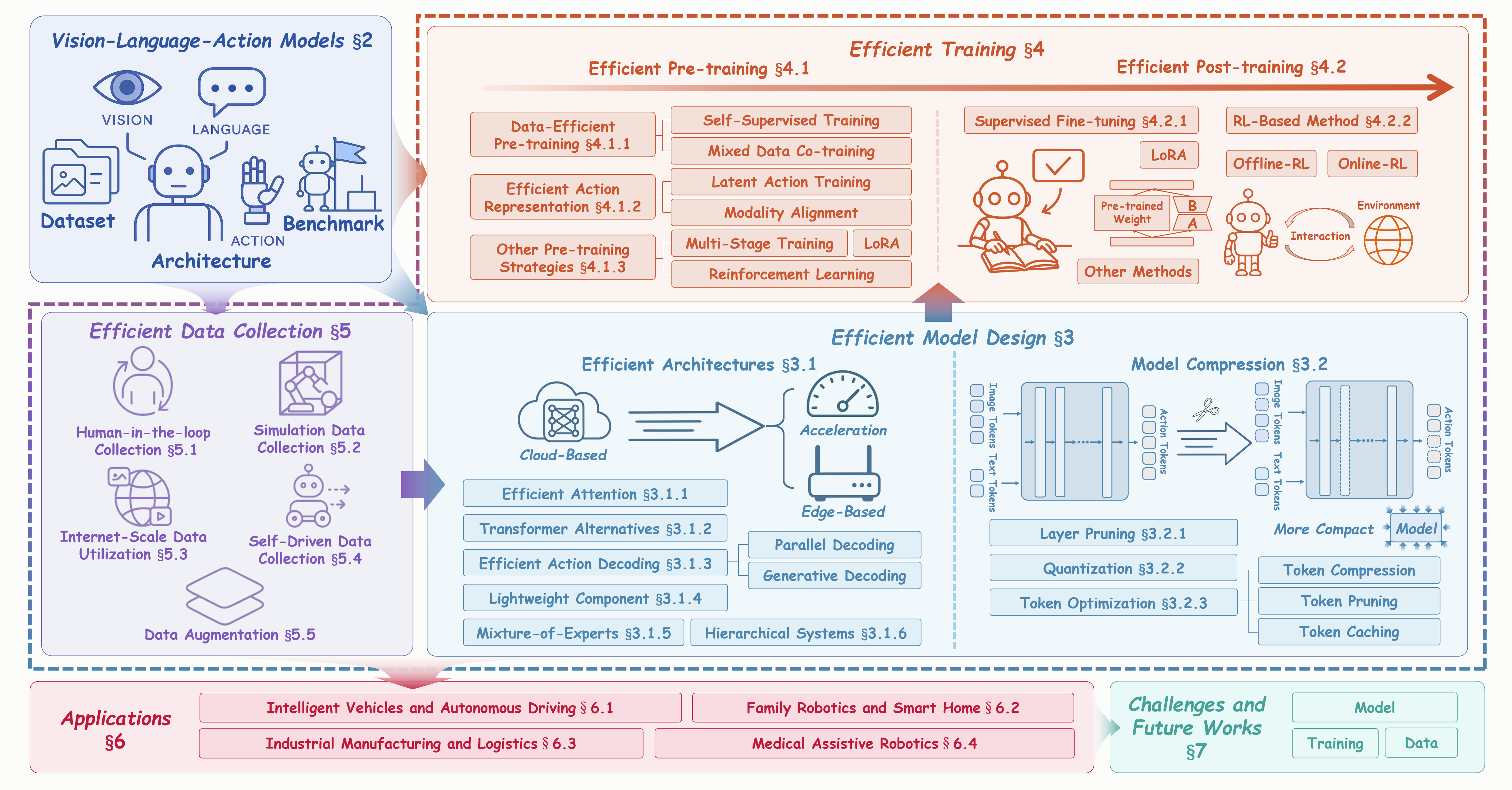
Figure: The Organization of Our Survey. We systematically categorize efficient VLAs into three core pillars: (1) Efficient Model Design, encompassing efficient architectures and model compression techniques, (2) Efficient Training, covering efficient pre-training and post-training strategies, and (3) Efficient Data Collection, including efficient data collection and augmentation methods. The framework also reviews VLA foundations, key applications, challenges, and future directions, establishing the groundwork for advancing scalable embodied intelligence.
Abstract
Vision-Language-Action models (VLAs) represent a significant frontier in embodied intelligence, aiming to bridge digital knowledge with physical-world interaction. Despite their remarkable performance, foundational VLAs are hindered by the prohibitive computational and data demands inherent to their large-scale architectures. While a surge of recent research has focused on enhancing VLA efficiency, the field lacks a unified framework to consolidate these disparate advancements. To bridge this gap, this survey presents the first comprehensive review of Efficient Vision-Language-Action models (Efficient VLAs) across the entire model-training-data pipeline. Specifically, we introduce a unified taxonomy to systematically organize the disparate efforts in this domain, categorizing current techniques into three core pillars: (1) Efficient Model Design, focusing on efficient architectures and model compression; (2) Efficient Training, which reduces computational burdens during model learning; and (3) Efficient Data Collection, which addresses the bottlenecks in acquiring and utilizing robotic data. Through a critical review of state-of-the-art methods within this framework, this survey not only establishes a foundational reference for the community but also summarizes representative applications, delineates key challenges, and charts a roadmap for future research. We maintain a continuously updated project page to track our latest developments: https://evla-survey.github.io/.
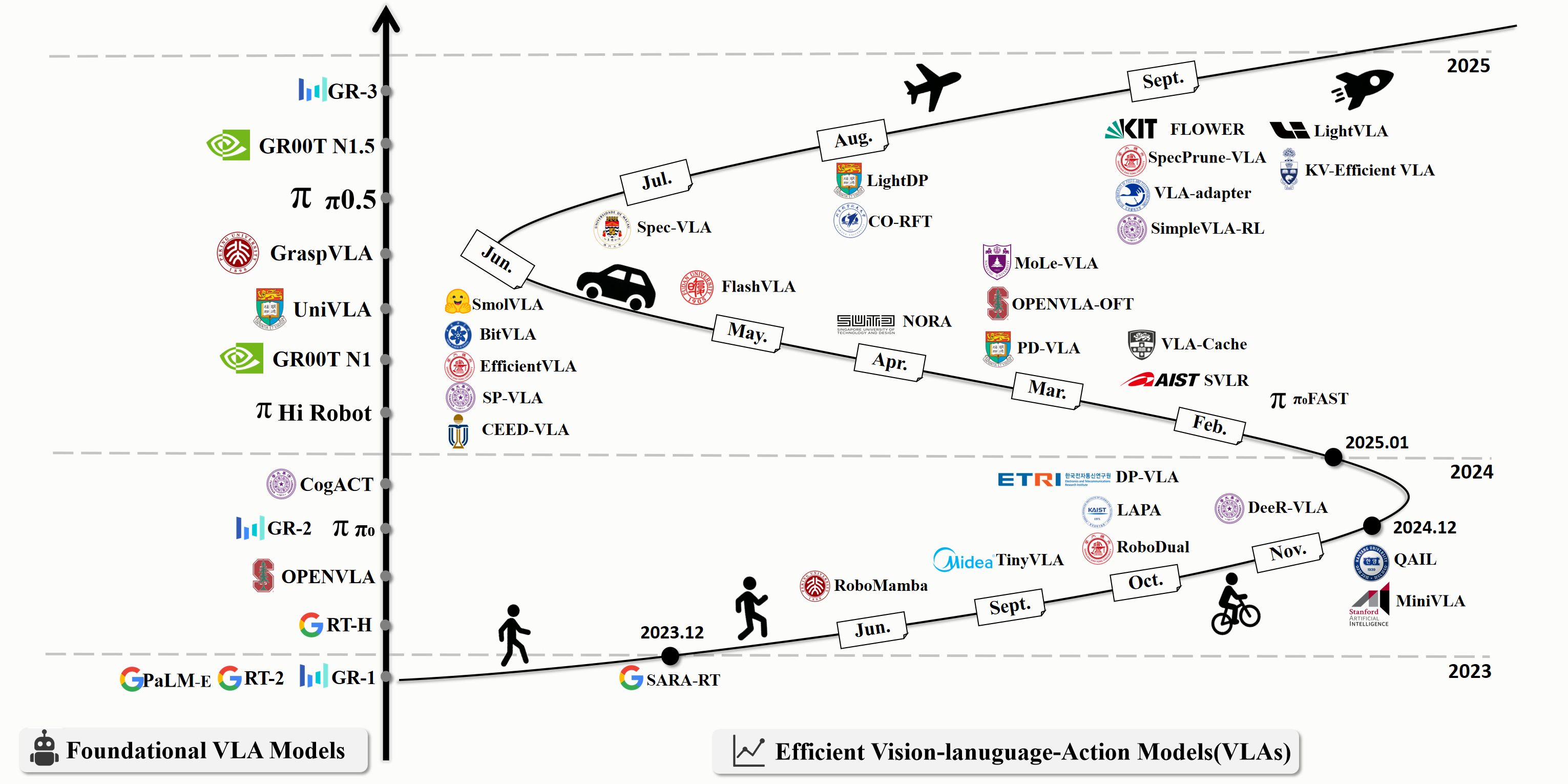
Figure: Timeline of Foundational VLAs and Efficient VLAs. The timeline illustrates the progression of foundational VLA models and efficient VLAs from 2023 to 2025, highlighting the explosive growth in enhancing the efficiency of VLA to bridge computational demands with real-world robotic deployment.
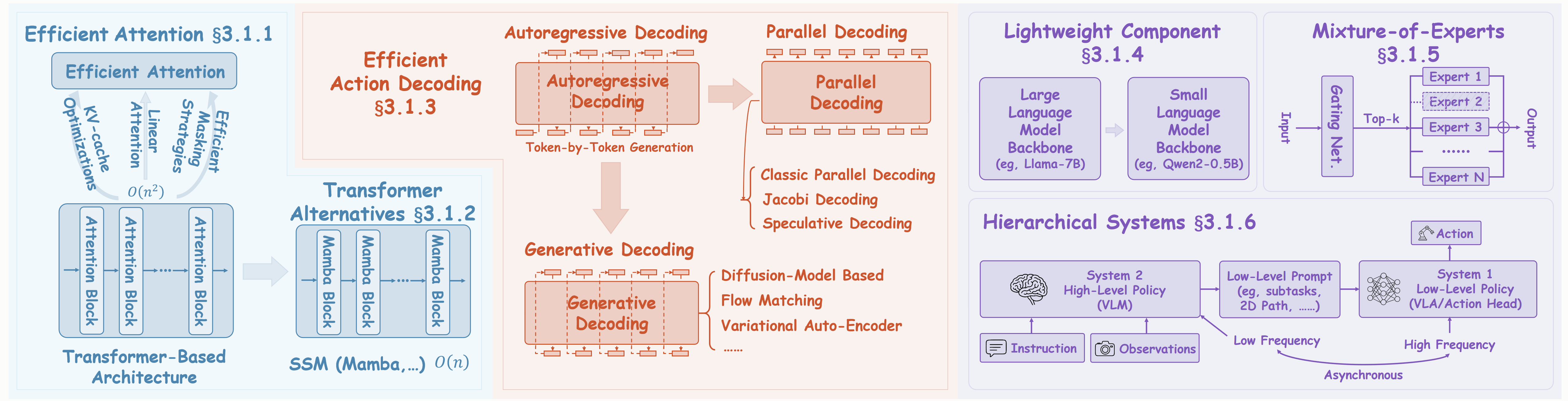
Figure: Key strategies for Efficient Architectures in VLAs. We illustrate six primary approaches: (a) Efficient Attention, mitigating the O(n²) complexity of standard self-attention; (b) Transformer Alternatives, such as Mamba; (c) Efficient Action Decoding, advancing from autoregressive generation to parallel and generative methods; (d) Lightweight Components, adopting smaller model backbones; (e) Mixture-of-Experts, employing sparse activation via input routing; and (f) Hierarchical Systems, which decouple high-level VLM planning from low-level VLA execution.
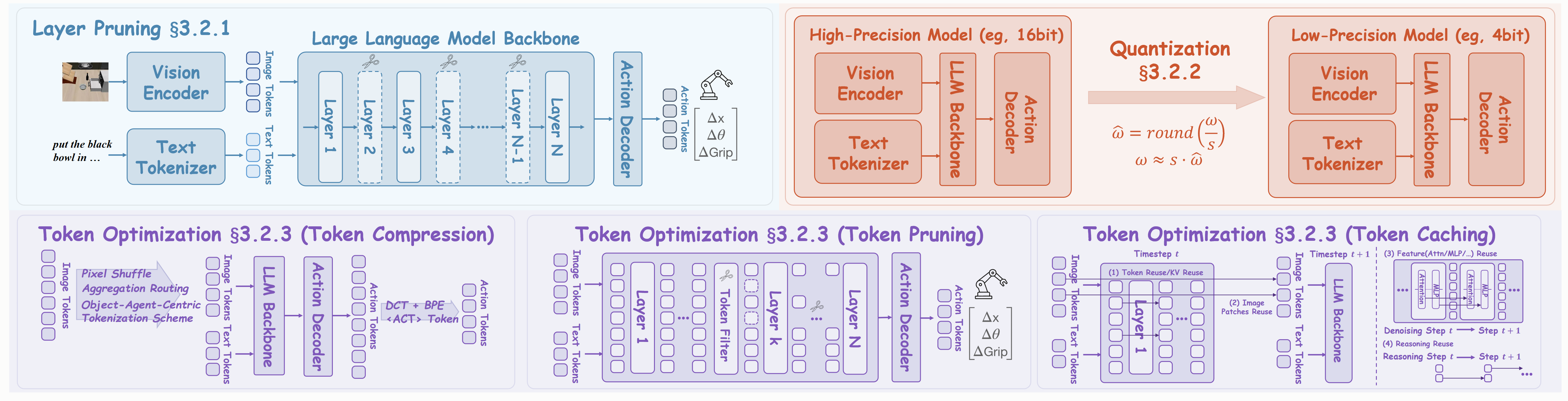
Figure: Key strategies for Model Compression in VLAs. We illustrate three primary approaches: (a) Layer Pruning, which removes redundant layers to reduce model depth and computational cost; (b) Quantization, which reduces the numerical precision of model parameters to decrease memory footprint and accelerate inference; and (c) Token Optimization, which minimizes the number of processed tokens via token compression (merging tokens), token pruning (dropping non-essential tokens), and token caching (reusing static tokens).
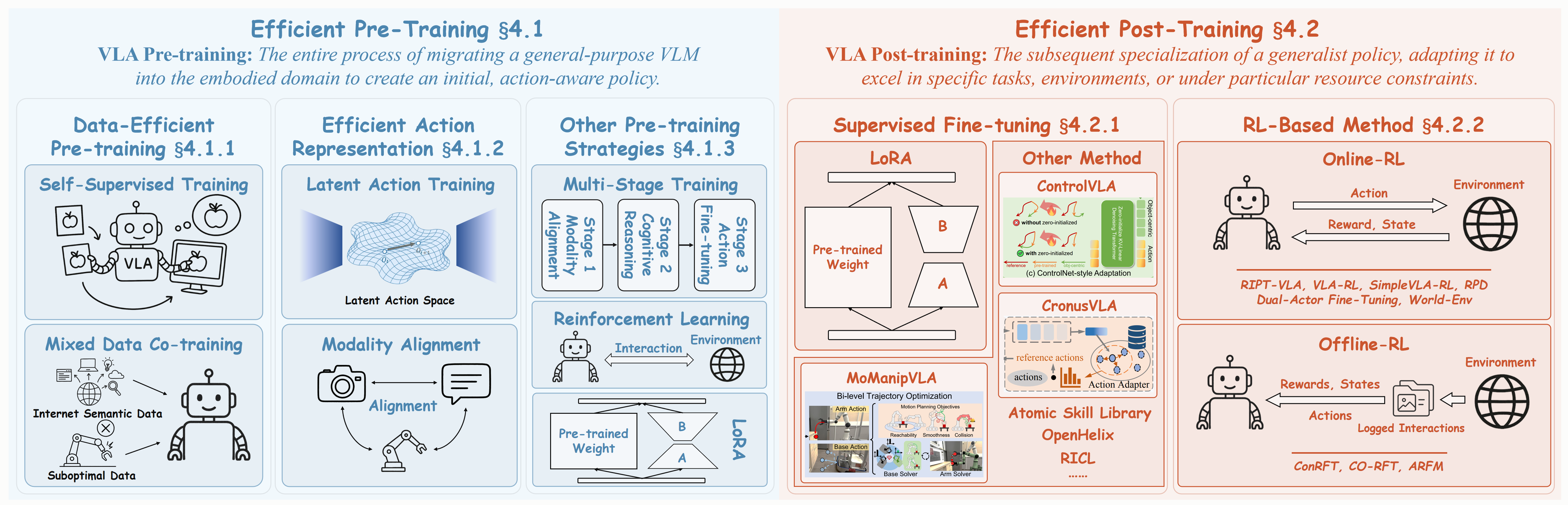
Figure: Key strategies for Efficient Training in VLAs, divided into two main stages.(a) Efficient Pre-Training migrates general-purpose VLMs into the embodied domain to create an initial, action-aware policy, encompassing Data-Efficient Pre-training, Efficient Action Representation, and Other Pre-training Strategies. (b) Efficient Post-Training subsequently specializes this policy for specific tasks, leveraging Supervised Fine-tuning and RL-Based Methods.
Figure: Taxonomy of Efficient Data Collection Strategies in VLAs. This figure illustrates the primary approaches under efficient data collection, encompassing human-in-the-loop, simulated, reusability-oriented, self-driven, and augmentative techniques for scalable acquisition of high-quality robotic datasets while minimizing resource overhead.
Paper List
Statistics Bar
0Total Papers
0Model Design
0Training
0Data Collection
Search and Filter Container
Search Box
Main Category Filters
Main Categories:
Subcategory Filters for Model Design
Medium Categories:
Add medium categories here
Subcategory Filters for Training
Medium Categories:
Add medium categories here
Subcategory Filters for Data Collection
Medium Categories:
Add medium categories here
Paper Table
Title
Year
Venue
Categories
Papers will be inserted here by JavaScript
No papers found matching your criteria.
Citation
@misc{yu2025efficientvlassurvey,
title={A Survey on Efficient Vision-Language-Action Models},
author={Zhaoshu Yu and Bo Wang and Pengpeng Zeng and Haonan Zhang and Ji Zhang and Lianli Gao and Jingkuan Song and Nicu Sebe and Heng Tao Shen},
year={2025},
eprint={2510.24795},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2510.24795},
}